
噪声、多人说话、声音重叠……这些语音识别的大难题,一直是国际多通道语音分离和识别大赛CHiME所聚焦的任务,而且任务难度逐年提升。
作为“最难语音识别任务”之称的语音领域国际权威赛事,CHiME(Computational Hearing in Multisource Environments)从2011年发起,今年已是第八届。
当地时间9月6日,CHiME 2024 Workshop在希腊科斯岛国际会议中心举行,官方组委会现场公布了大赛成绩:科大讯飞与中科大语音及语言信息处理国家工程研究中心(NERC-SLIP)、国家智能语音创新中心联合团队,在参与的全新Task 2——“会议室场景远场多人语音识别”(NOTSOFAR)任务中获得全部两个赛道的第一名,连续五届收获冠军。

CHiME的“进化之路”:
会议室场景识别再掀新挑战浪潮
CHiME挑战赛致力于聚集学术界和工业界优秀力量,持续突破语音识别技术水平,不断在更高噪声、更高混响、更高对话复杂度的场景下提出具有创新性的解决方案,解决著名的“鸡尾酒会问题”——即在复杂的声学环境中,由于多种声源同时存在且相互混合,导致接收设备或人耳接收到的信号是多个声源的叠加信号,如何从中有效地分离出各个独立的声源信号。
CHiME每一届的任务设置和难度都在不断变化和提升,语音识别任务的复杂性和挑战性持续加强:
2016年,CHiME-4聚焦于日常嘈杂环境中的单人语音识别,参赛者需要面对真实世界的噪声环境实现高精度语音识别;
2018年,CHiME-5任务升级为多房间的4人家庭聚会环境,增加多人对话、远场多阵列和复杂背景噪声挑战,考察测试家庭聚会场景中自由交谈风格下的远场多人语音识别效果;2020、2023年的CHiME-6和CHiME-7,则分别对说话人分离、语音识别系统鲁棒性提出更高要求;
2024年,CHiME-8新增了Task2任务“会议室场景远场多人语音识别”(NOTSOFAR),聚焦单一录音设备下的远场会议语音转写。新任务要求在4到8人的会议室场景中,进行多通道语音识别和说话人分离。该任务由微软组织,吸引了约翰霍普金斯大学、捷克布尔诺理工大学、奈良先端科学技术大学院大学、西北工业大学、南京大学、腾讯天籁实验室等国内外知名研究机构、高校和企业参与角逐。

与前几届相比,此次比赛的新任务类型面向会议室场景,难度再次提升:
会议场景覆盖了30个不同的会议室,每个会议室尺寸、布局、建筑材料和声学特性不同,会议主题也不相同;
识别人数从固定的4人增加到动态的4到8人;
多人同时讲话导致了语音重叠、打断,以及说话人快速切换。其中,测试集语音重叠比例平均达到了39.5%;
需要处理不同的声学场景,比如说话人起身在白板附近说话、边走边说,声音的距离和音量都会有变化;
还要处理不同类型的干扰噪声,比如关门声、电话铃声、空调噪声等。
CHiME-8的Task2任务设有两个主要赛道:单通道语音识别(SC, Single-channel)和已知麦克风阵型的多通道语音识别(MC, Multi-channel)。前者使用多个单通道设备录音,后者使用已知阵型布局的麦克风阵列设备。系统将根据说话人相关的tcpWER指标进行排名,该指标通过对不同说话人分别计算词错误率,综合评估了说话人分离的准确性和语音识别的整体效果。
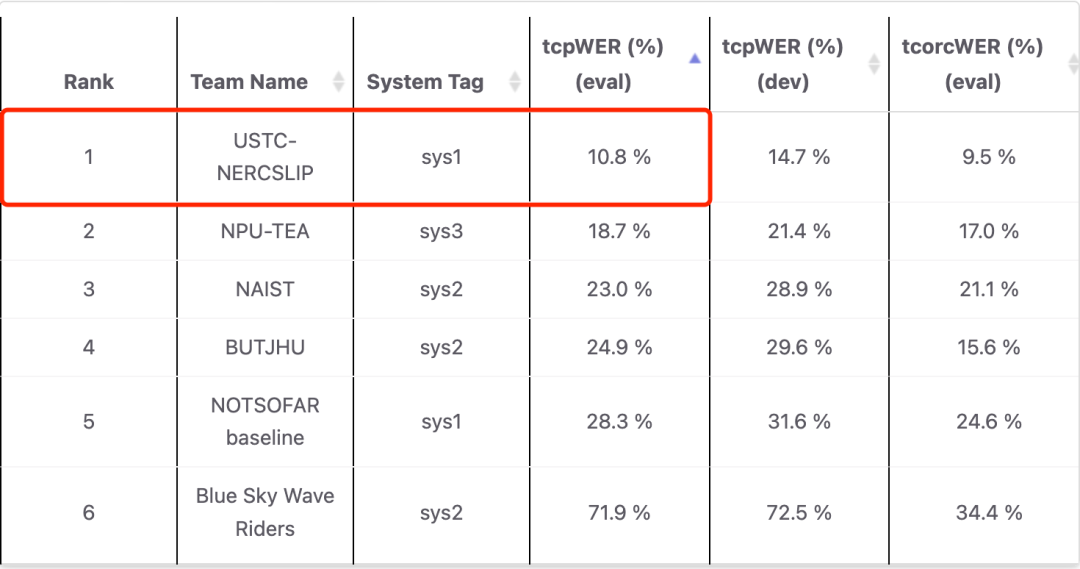
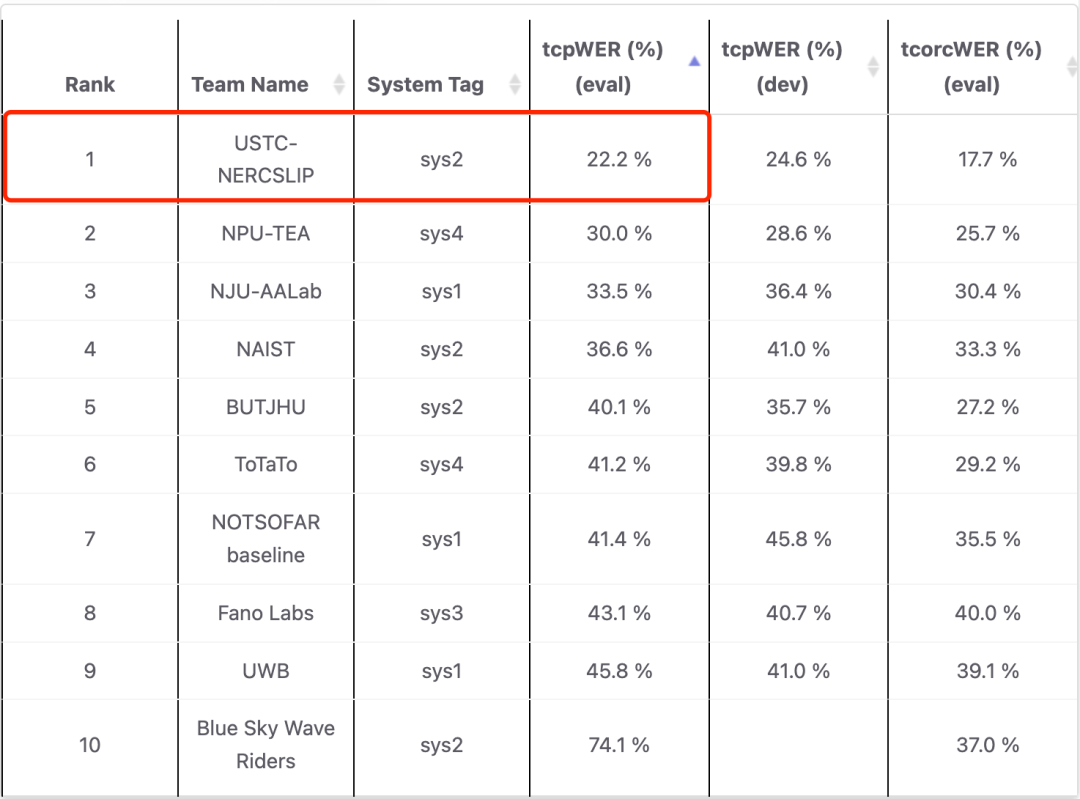
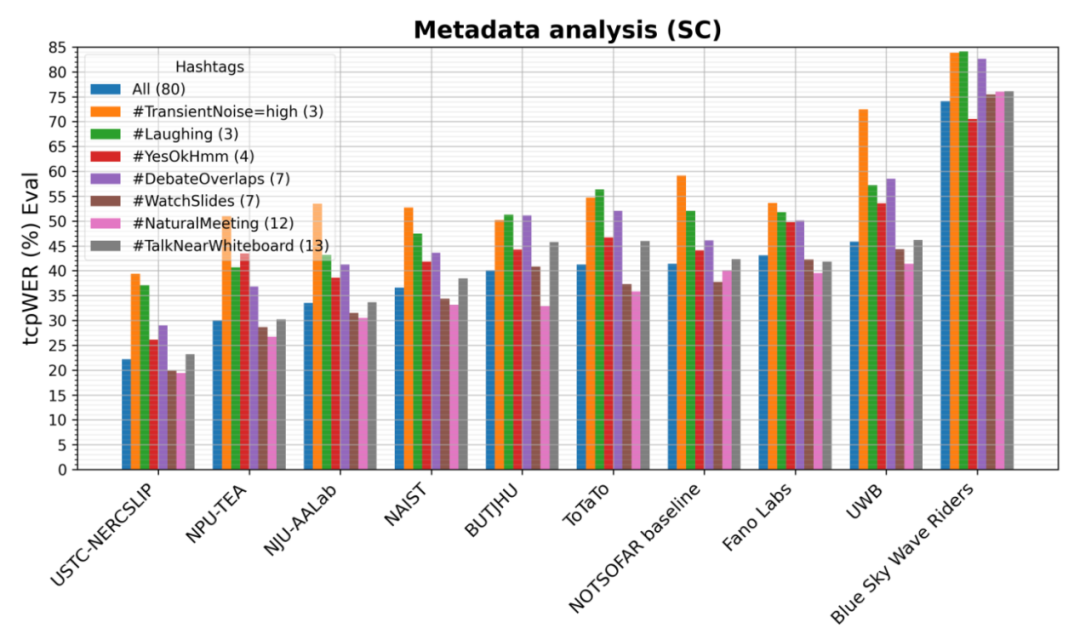
科大讯飞联合团队(USTC-NERCSLIP)参加了所有两个赛道,在单通道赛道上语音识别错误率(tcpWER)降至22.2%,领先第二名30.0%,相比基线系统降低了46.4%;在多通道赛道上语音识别错误率(tcpWER)降低至10.8%,领先第二名46.4%,相比基线系统降低了61.8%;且在细分的7个声学场景下的表现都优于其他团队,体现了所提交系统在多种噪声、会议特性环境中的鲁棒性。
迎接新挑战,
我们定义了哪些关键问题和解决方案?
复杂的会议场景中,如何实现高精准的语音识别和说话人分离?科大讯飞联合团队针对新场景中的关键问题,基于长期在语音转写领域的技术积累以及语音识别技术在办公等场景落地应用中的实践和反馈,创新并采用了多种技术方法,突破了人数估计、语音重叠、远场混响、人员移动及对话风格随意等难关。
基于重叠声检测和语音分离的多说话人迭代聚类角色分离算法(Speaker Clustering Based on Overlap Detection and Speech Separation)
该方法旨在解决高噪声、多说话人高度重叠和说话人时长分布不均场景下说话人角色分离不准、人数漏估等问题。针对多个说话人同时说话、声纹特征提取不准的情况,团队设计了重叠声检测模块,可以利用该模块区分重叠和非重叠片段,并通过语音分离模块将重叠片段中的每个说话人声音独立分离出来。
同时,网络结构更深、短时效果更优的ResNet-221结构用于提取分离语音和非重叠段原始语音的声纹特征,并结合重叠段近邻限制的聚类算法,极大降低了人数估计错误率,有效提升了角色分离的准确度。
此外,团队还基于第一轮生成的GSS(Guided Source Separation)分离音频进行迭代聚类,进一步修正音色相似或分离音频畸变导致的说话人数错估、角色错分等情况,从而大幅度降低了后续语音识别任务的错误率,为复杂语音场景下的应用提供了更为可靠的技术支持。
长短时空间滤波(Long-Short Spatial Filter)
该方案基于麦克风阵列并结合说话人角色分离技术,在空间层面解决会议远场语音识别中存在的背景噪声、语音重叠、音量过低、说话人走动等难点问题。在提出的多说话人迭代聚类角色分离算法基础上,针对会议场景特点,提出长短时空间滤波(Long-Short Spatial Filter)的方案,通过CACGMM(Complex Angular Central Gaussian Mixture Model)在长时语音段上对每个说话人建模,有效避免某个说话人有效语音片段过少导致的估计偏差。
同时,为了避免说话人走动带来的长时信息估计不准确,在短时语音段上,结合长时估计统计量和角色分离提供更加精细的时频点掩蔽信号(Time-Frequency Mask),有效捕捉移动说话人变化的空间信息,得到最终更加鲁棒和精确的说话人时频分布估计。最终波束形成算法在上述时频点掩蔽信号指导下,通过准确滤除背景噪声和其他方向干扰人声,有效解决远场信号语音重叠和音量较低问题,从而提升下游识别任务性能。
自适应声学与语言模型方案(Adaptive Acoustic and Language Model Method)
该方案专注于提升复杂会议场景中的语音识别性能,在声学模型方面,根据输入音频的特征信息自动选择最合适的专家网络,以有效捕捉不同说话人的语音特征和应对各种环境噪声。在语言模型方面,结合上下文信息,通过对话历史和场景关键词进行动态调整,实时优化语言模型的生成策略。这使得模型能够理解当前对话的主题和参与者的说话习惯,从而生成更合适的识别结果,有效提升了语音识别在复杂场景中的鲁棒性和准确性。
大模型时代:
语音识别走向何方?
此次挑战赛中涉及的语音识别相关技术,目前已在讯飞听见、讯飞智能办公本、讯飞智能录音笔等软硬件产品中实现了落地应用,尤其针对会议室场景下的会议转写、发言记录等,相比过去有了更多、更好的效果提升。
讯飞听见智能会议系统实现了安全、快速、高效、准确的语音识别和转写,在国内外各类型会议、办公、教学培训、大会演讲等发挥着作用,已累计服务超过500万间会议室。

讯飞智能办公本的核心功能亮点便是会议场景下的多人语音精准识别,不久前新发布的智能办公本Air2采用四麦阵列,并且优化了降噪算法、消除手写噪声,同时结合最新的语义转折点识别算法让说话人识别达到真正的好用。
讯飞智能录音笔也在各类商务会议、大型峰会等场景助力高效信息记录,实现了区分讲话人、语义智能分段、语气词过滤等,录音转文字识别准确率持续提升。

大模型的出现与发展,不仅显著提升了语音识别的准确率,也带来了更多可能。例如在讯飞星火V4.0发布会上,基于星火大模型的多模态能力能够在噪音场景下实现三人重叠说话情况下的音色分离,还能实时转写出每个人的语音,突破了多人混叠场景下的极复杂语音转写;同时星火语音大模型还发布了多语种多方言免切换的语音识别能力,可支持37个语种、37个方言“自由对话”。
值得一提的是,CHiME-8比赛也选择了一个大模型作为官方基线模型,充分证明了业界对于大模型赋能语音识别这一趋势的认可。讯飞联合团队在此次竞赛中取得好成绩的关键,也离不开在大模型基础上,针对复杂场景引入WavLM等增强特征表达,融合多专家混合模型(MoE)强化了大模型场景的信息解耦。
未来,如何利用大模型进一步提升语音前处理和预训练技术,将成为推动语音识别技术突破的关键。借鉴讯飞收获今年国家科学技术进步奖一等奖项目中的语音属性解耦、语音信号时空分离等创新思路,可以对原始语音信号进行更精细化的处理,并基于此进行更有针对性的预训练,从而突破现有技术瓶颈。
基于这样的尝试,讯飞星火语音大模型发布后,首批37个主流语种的语音识别效果超过了Whisper v3,超拟人语音合成和一句话合成在自然度拟人度上也表现突出。上周,星火语音大模型的最新进展——星火极速超拟人交互也正式全民开放体验,实现更快响应、更懂情绪、更加灵活、更加百变的语音交互新体验。
未来,科大讯飞也将在挑战难度不断攀升的智能语音“登山之旅”上保持初心,以持续的源头技术创新突破叩响万物互联时代的大门。
(来源:科大讯飞的财富号 2024-09-06 19:43) [点击查看原文]
